数组是保存一组对象的最有效的方式,如果想要保存一组基本类型数据,也推荐使用数组。但是数组具有固定的大小尺寸,而且在更一般的情况下,在写程序的时候并不知道将需要多少个对象,或者是否需要更复杂的方式来存储对象,因此数组尺寸固定这一限制就显得太过受限了。
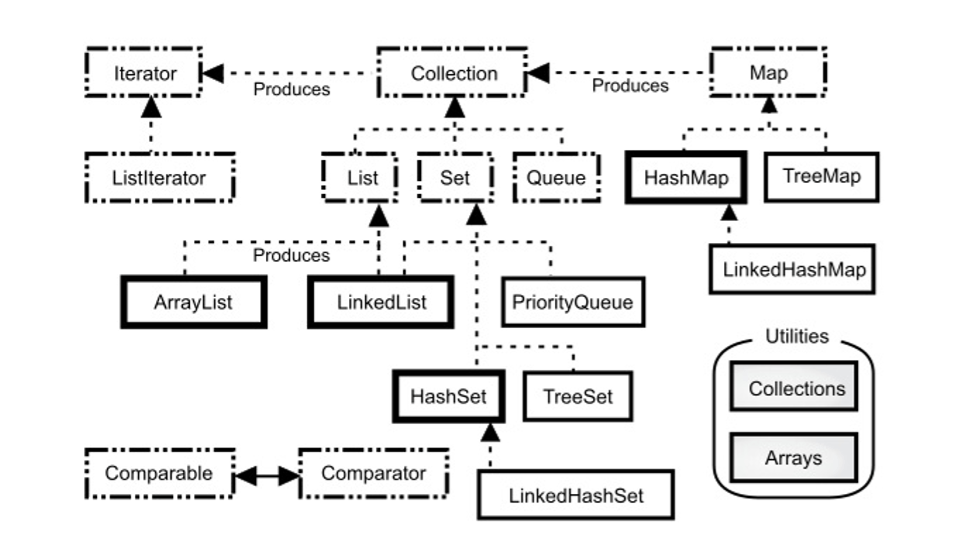
java.util 库提供了一套相当完整的 集合类(collection classes)来解决这个问题,其中基本的类型有 List 、 Set 、 Queue 和 Map。这些类型也被称作 容器类(container classes),但我将使用 Java 类库使用的术语。集合提供了完善的方法来保存对象,可以使用这些工具来解决大量的问题。
- ArrayList
- LinkedList
Set检索元素的最快方法
HashSet
TreeSet 关心存储顺序
LinkedHashSet 关心存储顺序
HashMap 键和值保存顺序不是插入顺序,因为 HashMap 实现使用了非常快速的算法来控制顺序
TreeMap 通过比较结果的升序来保存键
LinkedHashMap 在保持 HashMap 查找速度的同时按键的插入顺序保存键
基本概念
Java 集合类库采用 “持有对象”(holding objects)的思想,并将其分为两个不同的概念,表示为类库的基本接口:
- 集合(Collection) :一个独立元素的序列,这些元素都服从一条或多条规则。List 必须以插入的顺序保存元素, Set 不能包含重复元素, Queue 按照 排队规则 来确定对象产生的顺序(通常与它们被插入的顺序相同)。
- 映射(Map) : 一组成对的 “键值对” 对象,允许使用键来查找值。 ArrayList 使用数字来查找对象,因此在某种意义上讲,它是将数字和对象关联在一起。 map 允许我们使用一个对象来查找另一个对象,它也被称作_关联数组_(associative array),因为它将对象和其它对象关联在一起;或者称作 字典(dictionary),因为可以使用一个键对象来查找值对象,就像在字典中使用单词查找定义一样。 Maps 是强大的编程工具。
尽管并非总是可行,但在理想情况下,你编写的大部分代码都在与这些接口打交道,并且唯一需要指定所使用的精确类型的地方就是在创建的时候。因此,可以像下面这样创建一个 List :
List<Apple> apples = new ArrayList<>();List<Apple> apples = new ArrayList<>();请注意, ArrayList 已经被向上转型为了 List ,这与之前示例中的处理方式正好相反。使用接口的目的是,如果想要改变具体实现,只需在创建时修改它就行了,就像下面这样:
List<Apple> apples = new LinkedList<>();List<Apple> apples = new LinkedList<>();因此,应该创建一个具体类的对象,将其向上转型为对应的接口,然后在其余代码中都是用这个接口。
这种方式并非总是有效的,因为某些具体类有额外的功能。例如, LinkedList 具有 List 接口中未包含的额外方法,而 TreeMap 也具有在 Map 接口中未包含的方法。如果需要使用这些方法,就不能将它们向上转型为更通用的接口。
Collection 接口概括了_序列_的概念——一种存放一组对象的方式。下面是个简单的示例,用 Integer 对象填充了一个 Collection (这里用 ArrayList 表示),然后打印集合中的每个元素:
@startuml
class ArrayList {
+ ...
}
ArrayList --> Collection
interface Iterable {
+ default void forEach();
+ Iterator<T> iterator();
+ default Spliterator<T> spliterator();
}
Collection --> Iterable
interface Collection {
+ int size();
+ boolean isEmpty();
+ boolean contains(Object o);
+ Iterator<E> iterator();
+ Object[] toArray();
+ boolean add(E e);
+ boolean remove(Object o);
+ boolean addAll(Collection<? extends E> c);
+ boolean removeAll(Collection<?> c);
+ ...
}
@enduml@startuml
class ArrayList {
+ ...
}
ArrayList --> Collection
interface Iterable {
+ default void forEach();
+ Iterator<T> iterator();
+ default Spliterator<T> spliterator();
}
Collection --> Iterable
interface Collection {
+ int size();
+ boolean isEmpty();
+ boolean contains(Object o);
+ Iterator<E> iterator();
+ Object[] toArray();
+ boolean add(E e);
+ boolean remove(Object o);
+ boolean addAll(Collection<? extends E> c);
+ boolean removeAll(Collection<?> c);
+ ...
}
@enduml添加元素组
在 java.util 包中的 Arrays 和 Collections 类中都有很多实用的方法,可以在一个 Collection 中添加一组元素。
@startuml
class Arrays {
+ ...
// 阈值:集合大小超过阈值,进行并行排序算法
+ private static final int MIN_ARRAY_SORT_GRAN;
+ static void rangeCheck(int arrayLength, int fromIndex, int toIndex)
+ public static void sort(int[] a) // 使用 DualPivotQuicksort 排序算法进行排序
+ public static void sort(int[] a, int fromIndex, int toIndex)
+ public static void sort(long[] a)
+ public static void sort(short[] a)
+ public static void sort(char[] a, int fromIndex, int toIndex)
+ public static void sort(byte[] a)
+ public static void sort(byte[] a, int fromIndex, int toIndex)
+ public static void sort(float[] a)
+ public static void sort(float[] a, int fromIndex, int toIndex)
+ public static void sort(double[] a)
+ public static void sort(double[] a, int fromIndex, int toIndex)
+ public static void parallelSort(byte[] a) // 并行排序,是否进行和MIN_ARRAY_SORT_GRAN有关
+ public static <T extends Comparable<? super T>>void parallelSort(T[] a, int fromIndex, int toIndex)
+ public static void sort(Object[] a)
+ private static void legacyMergeSort(Object[] a)
+ public static void sort(Object[] a, int fromIndex, int toIndex)
+ private static void swap(Object[] x, int a, int b)
}
@enduml@startuml
class Arrays {
+ ...
// 阈值:集合大小超过阈值,进行并行排序算法
+ private static final int MIN_ARRAY_SORT_GRAN;
+ static void rangeCheck(int arrayLength, int fromIndex, int toIndex)
+ public static void sort(int[] a) // 使用 DualPivotQuicksort 排序算法进行排序
+ public static void sort(int[] a, int fromIndex, int toIndex)
+ public static void sort(long[] a)
+ public static void sort(short[] a)
+ public static void sort(char[] a, int fromIndex, int toIndex)
+ public static void sort(byte[] a)
+ public static void sort(byte[] a, int fromIndex, int toIndex)
+ public static void sort(float[] a)
+ public static void sort(float[] a, int fromIndex, int toIndex)
+ public static void sort(double[] a)
+ public static void sort(double[] a, int fromIndex, int toIndex)
+ public static void parallelSort(byte[] a) // 并行排序,是否进行和MIN_ARRAY_SORT_GRAN有关
+ public static <T extends Comparable<? super T>>void parallelSort(T[] a, int fromIndex, int toIndex)
+ public static void sort(Object[] a)
+ private static void legacyMergeSort(Object[] a)
+ public static void sort(Object[] a, int fromIndex, int toIndex)
+ private static void swap(Object[] x, int a, int b)
}
@endumlArrays.asList() 方法接受一个数组或是逗号分隔的元素列表(使用可变参数),并将其转换为 List 对象。 Collections.addAll() 方法接受一个 Collection 对象,以及一个数组或是一个逗号分隔的列表,将其中元素添加到 Collection 中。下边的示例展示了这两个方法,以及更通用的 addAll() 方法,所有 Collection 类型都包含该方法:
#again 【再次整理】
import java.util.*;
public class AddingGroups {
public static void main(String[] args) {
Collection<Integer> collection =
new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] moreInts = { 6, 7, 8, 9, 10 };
collection.addAll(Arrays.asList(moreInts));
Collections.addAll(collection, 11, 12, 13, 14, 15);
Collections.addAll(collection, moreInts);
List<Integer> list = Arrays.asList(16,17,18,19,20);
list.set(1, 99);
}
}import java.util.*;
public class AddingGroups {
public static void main(String[] args) {
Collection<Integer> collection =
new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] moreInts = { 6, 7, 8, 9, 10 };
collection.addAll(Arrays.asList(moreInts));
Collections.addAll(collection, 11, 12, 13, 14, 15);
Collections.addAll(collection, moreInts);
List<Integer> list = Arrays.asList(16,17,18,19,20);
list.set(1, 99);
}
}Collection 的构造器可以接受另一个 Collection,用它来将自身初始化。因此,可以使用 Arrays.asList() 来为这个构造器产生输入。但是, Collections.addAll() 运行得更快,而且很容易构建一个不包含元素的 Collection ,然后调用 Collections.addAll() ,因此这是首选方式。
Collection.addAll() 方法只能接受另一个 Collection 作为参数,因此它没有 Arrays.asList() 或 Collections.addAll() 灵活。这两个方法都使用可变参数列表。
也可以直接使用 Arrays.asList() 的输出作为一个 List ,但是这里的底层实现是数组,没法调整大小。如果尝试在这个 List 上调用 add() 或 delete(),由于这两个方法会尝试修改数组大小,所以会在运行时得到 “Unsupported Operation(不支持的操作)” 错误:
import java.util.*;
class Snow {}
class Powder extends Snow {}
class Light extends Powder {}
class Heavy extends Powder {}
class Crusty extends Snow {}
class Slush extends Snow {}
public class AsListInference {
public static void main(String[] args) {
List<Snow> snow1 = Arrays.asList(
new Crusty(), new Slush(), new Powder());
List<Snow> snow2 = Arrays.asList(
new Light(), new Heavy());
List<Snow> snow3 = new ArrayList<>();
Collections.addAll(snow3,
new Light(), new Heavy(), new Powder());
snow3.add(new Crusty());
List<Snow> snow4 = Arrays.<Snow>asList(
new Light(), new Heavy(), new Slush());
}
}import java.util.*;
class Snow {}
class Powder extends Snow {}
class Light extends Powder {}
class Heavy extends Powder {}
class Crusty extends Snow {}
class Slush extends Snow {}
public class AsListInference {
public static void main(String[] args) {
List<Snow> snow1 = Arrays.asList(
new Crusty(), new Slush(), new Powder());
List<Snow> snow2 = Arrays.asList(
new Light(), new Heavy());
List<Snow> snow3 = new ArrayList<>();
Collections.addAll(snow3,
new Light(), new Heavy(), new Powder());
snow3.add(new Crusty());
List<Snow> snow4 = Arrays.<Snow>asList(
new Light(), new Heavy(), new Slush());
}
}在 snow4 中,注意 Arrays.asList() 中间的 “hint”,告诉编译器 Arrays.asList() 生成的结果 List 类型的实际目标类型是什么。这称为 显式类型参数说明(explicit type argument specification)。
列表 List
Lists 承诺以特定顺序保存元素。 List 接口在 Collection 的基础上添加了许多方法,允许在 List 的中间插入和删除元素。
有两种类型的 List :
- 基本的 ArrayList ,擅长随机访问元素,但在 List 中间插入和删除元素时速度较慢。
- LinkedList ,它通过代价较低的在 List 中间进行的插入和删除操作,提供了优化的顺序访问。 LinkedList 对于随机访问来说相对较慢,但它具有比 ArrayList 更大的特征集。
下面的示例导入 typeinfo.pets ,超前使用了类型信息一章中的类库。这个类库包含了 Pet 类层次结构,以及用于随机生成 Pet 对象的一些工具类。此时不需要了解完整的详细信息,只需要知道两点:
- 有一个 Pet 类,以及 Pet 的各种子类型。
- 静态的 Pets.arrayList() 方法返回一个填充了随机选取的 Pet 对象的 ArrayList:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
// 打乱顺序
Collections.shuffle(list);
System.out.println(list);List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
// 打乱顺序
Collections.shuffle(list);
System.out.println(list);LinkedList根据下标取数据为什么比ArrayList慢:
- ArrayList底层是数组,使用get()方法, 直接取的是数组对应下标中的值
- LinkedList底层是链表, 数据结构上一定不存在下标这么个概念。 只能对总数遍历,然后取循环下标的值。
使用迭代器访问,两者速度差不多。
迭代器 Iterators
迭代器(也是一种设计模式)。
迭代器是一个对象,它在一个序列中移动并选择该序列中的每个对象,而客户端程序员不知道或不关心该序列的底层结构。另外,迭代器通常被称为 轻量级对象(lightweight object):创建它的代价小。因此,经常可以看到一些对迭代器有些奇怪的约束。例如,Java 的 Iterator 只能单向移动。这个 Iterator 只能用来:
- 使用 iterator() 方法要求集合返回一个 Iterator。 Iterator 将准备好返回序列中的第一个元素。
- 使用 next() 方法获得序列中的下一个元素。如果没有下一个元素,但是调用next会抛出异常 .
- 使用 hasNext() 方法检查序列中是否还有元素。
- 使用 remove() 方法将迭代器最近返回的那个元素删除。调用 remove() 之前必须先调用 next()
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
Iterator<Integer> iterator = list.iterator();
// hasNext() 方法检查序列中是否还有元素
while (iterator.hasNext()) {
// 如果没有下一个元素,但是调用next会抛出异常
Integer next = iterator.next();
System.out.println(next);
}
iterator = list.iterator();
int size = list.size();
for(int i = 0; i < size; i++) {
iterator.next(); // 获得序列中的下一个元素
// remove() 方法将迭代器最近返回的那个元素删除: 调用 remove() 之前必须先调用 next()
iterator.remove();
}
System.out.println(list); // 空
}public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
Iterator<Integer> iterator = list.iterator();
// hasNext() 方法检查序列中是否还有元素
while (iterator.hasNext()) {
// 如果没有下一个元素,但是调用next会抛出异常
Integer next = iterator.next();
System.out.println(next);
}
iterator = list.iterator();
int size = list.size();
for(int i = 0; i < size; i++) {
iterator.next(); // 获得序列中的下一个元素
// remove() 方法将迭代器最近返回的那个元素删除: 调用 remove() 之前必须先调用 next()
iterator.remove();
}
System.out.println(list); // 空
}ListIterator
ListIterator 是一个更强大的 Iterator 子类型,它只能由各种 List 类生成。
虽然 Iterator 只能向前移动,但 ListIterator 可以双向移动。
它还可以生成相对于迭代器在列表中指向的当前位置的后一个和前一个元素的索引,并且可以使用 set() 方法替换它访问过的最后一个元素。
可以通过调用 listIterator() 方法来生成指向 List 开头处的 ListIterator ,还可以通过调用 listIterator(n) 创建一个一开始就指向列表索引号为 n 的元素处的 ListIterator 。 下面的示例演示了所有这些能力:
- 支持双向移动
previous()、next() - 支持获取下标
previousIndex()、nextIndex() - 支持 listIterator(n) 创建一个一开始就指向列表索引号为 n 的元素处的
ListIterator
ListIterator<Integer> integerListIterator = list.listIterator();
integerListIterator.next();
if (integerListIterator.hasPrevious()) {
System.out.println(integerListIterator.previous());
}
while (integerListIterator.hasNext()) {
Integer next = integerListIterator.next();
System.out.println(next);
System.out.println(integerListIterator.previousIndex());
}ListIterator<Integer> integerListIterator = list.listIterator();
integerListIterator.next();
if (integerListIterator.hasPrevious()) {
System.out.println(integerListIterator.previous());
}
while (integerListIterator.hasNext()) {
Integer next = integerListIterator.next();
System.out.println(next);
System.out.println(integerListIterator.previousIndex());
}链表 LinkedList
LinkedList
- 实现了基本的 List*接口
- 在 List 中间执行插入和删除操作时,比 ArrayList更高
- 在随机访问操作效率方面比ArrayList逊色一些
追加了一些方法:使其可以被用作栈、队列或双端队列(deque)
在这些方法中,有些彼此之间可能只是名称有些差异,或者只存在些许差异,以使得这些名字在特定用法的上下文环境中更加适用(特别是在 Queue 中)。例如:
getFirst() 和 element() 是相同的,它们都返回列表的头部(第一个元素)而并不删除它,如果 List 为空,则抛出 NoSuchElementException 异常。 peek() 方法与这两个方法只是稍有差异,它在列表为空时返回 null 。
removeFirst() 和 remove() 也是相同的,它们删除并返回列表的头部元素,并在列表为空时抛出 NoSuchElementException 异常。 poll() 稍有差异,它在列表为空时返回 null 。
addFirst() 在列表的开头插入一个元素。
offer() 与 add() 和 addLast() 相同。 它们都在列表的尾部(末尾)添加一个元素。
removeLast() 删除并返回列表的最后一个元素。
返回一个元素
- 数组空的时候返回异常 NoSuchElementException
- getFirst()
- element()
- 空的时候返回null
- peek()
移除第一个元素并返回这个元素,数组空的时候返回异常NoSuchElementException。 返回移除的元素
list.removeFirst()list.remove()
移除第一个元素并返回这个元素,数组空的时候返回异常NoSuchElementException。 返回移除的元素
- list.poll()
移除最后一个元素并返回这个元素,数组空的时候返回异常null。 返回移除的元素
- list.removeLast()
添加第一个元素
- addFirst(x)
添加尾部元素
- list.offer(10);
- list.add(88);
- list.addLast(100);
LinkedList<Integer> list = new LinkedList<>();
System.out.println(list.peek());
list.add(1);
list.add(2);
list.add(3);
list.add(4);
if (!list.isEmpty()) {
// 返回一个元素,空的时候返回异常
System.out.println(list.getFirst());
System.out.println(list.element());
// 移除第一个元素,数组空的时候返回异常。 返回移除的元素
System.out.println(list.removeFirst());
// 移除最后一个元素,数组空的时候返回异常。 返回移除的元素
System.out.println(list.removeLast());
}
System.out.println(list);
// 添加第一个元素
list.addFirst(0);
System.out.println(list);
// 添加尾部元素
list.offer(10);
list.add(88);
list.addLast(100);
System.out.println(list);LinkedList<Integer> list = new LinkedList<>();
System.out.println(list.peek());
list.add(1);
list.add(2);
list.add(3);
list.add(4);
if (!list.isEmpty()) {
// 返回一个元素,空的时候返回异常
System.out.println(list.getFirst());
System.out.println(list.element());
// 移除第一个元素,数组空的时候返回异常。 返回移除的元素
System.out.println(list.removeFirst());
// 移除最后一个元素,数组空的时候返回异常。 返回移除的元素
System.out.println(list.removeLast());
}
System.out.println(list);
// 添加第一个元素
list.addFirst(0);
System.out.println(list);
// 添加尾部元素
list.offer(10);
list.add(88);
list.addLast(100);
System.out.println(list);堆栈 Stack
堆栈是 “后进先出”(LIFO)集合。它有时被称为 叠加栈(pushdown stack)
Java 1.0 中附带了一个 Stack 类,结果设计得很糟糕(为了向后兼容,我们永远坚持 Java 中的旧设计错误)。Java 6 添加了 ArrayDeque ,其中包含直接实现堆栈功能的方法:
Deque<String> stack = new ArrayDeque<>();
for (String s : "My dog has fleas".split(" ")) {
stack.push(s);
}
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}Deque<String> stack = new ArrayDeque<>();
for (String s : "My dog has fleas".split(" ")) {
stack.push(s);
}
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}集合 Set
Set 不保存重复的元素。 如果试图将相同对象的多个实例添加到 Set 中,那么它会阻止这种行为。 Set 最常见的用途是测试归属性,可以很轻松地询问某个对象是否在一个 Set 中。因此,查找通常是 Set 最重要的操作,因此通常会选择 HashSet 实现,该实现针对快速查找进行了优化。
Random rand = new Random(47);
Set<Integer> intset = new HashSet<>();
for(int i = 0; i < 10000; i++)
intset.add(rand.nextInt(30));
System.out.println(intset); Random rand = new Random(47);
Set<Integer> intset = new HashSet<>();
for(int i = 0; i < 10000; i++)
intset.add(rand.nextInt(30));
System.out.println(intset);早期 Java 版本中的 HashSet 产生的输出没有可辨别的顺序。
这是因为出于对速度的追求, HashSet 使用了散列,请参阅附录:集合主题一章。
由 HashSet 维护的顺序与 TreeSet 或 LinkedHashSet 不同,因为它们的实现具有不同的元素存储方式。 TreeSet 将元素存储在[红-黑树数据结构]中,而 HashSet 使用[散列函数]。 LinkedHashSet 因为查询速度的原因也使用了散列,但是看起来使用了链表来维护元素的插入顺序。显然,哈希算法已经更改,现在 Integer 按顺序排序。 但是,您不应该依赖此行为。
映射 Map
..
队列 Queue
队列是一个典型的 “先进先出”(FIFO)集合。 即从集合的一端放入事物,再从另一端去获取它们,事物放入集合的顺序和被取出的顺序是相同的。队列通常被当做一种可靠的将对象从程序的某个区域传输到另一个区域的途径。队列在并发编程中尤为重要,因为它们可以安全地将对象从一个任务传输到另一个任务。
入:
- add
- offer
出: - remove 没有元素会抛出异常
- poll
Queue<Integer> queue = new LinkedList<>();
Random rand = new Random(47);
for(int i = 0; i < 10; i++) {
// 在队列的尾部插入一个元素
queue.offer(rand.nextInt(i + 10));
}
System.out.println(queue);
//peek()都返回队头元素而不删除它,无数据返回 null
while(queue.peek() != null) {
// 没有元素会抛出异常
System.out.print(queue.remove() + " ");
}
// 没有元素会返回null
Integer poll2 = queue.poll();Queue<Integer> queue = new LinkedList<>();
Random rand = new Random(47);
for(int i = 0; i < 10; i++) {
// 在队列的尾部插入一个元素
queue.offer(rand.nextInt(i + 10));
}
System.out.println(queue);
//peek()都返回队头元素而不删除它,无数据返回 null
while(queue.peek() != null) {
// 没有元素会抛出异常
System.out.print(queue.remove() + " ");
}
// 没有元素会返回null
Integer poll2 = queue.poll();优先级队列 PriorityQueue
如果构建了一个消息传递系统,某些消息比其他消息更重要,应该尽快处理,而不管它们何时到达。在 Java 5 中添加了 PriorityQueue ,以便自动实现这种行为。
可用定义规则,觉得哪条数据先被消费掉。
当在 PriorityQueue 上调用 offer() 方法来插入一个对象时,该对象会在队列中被排序。
默认的排序使用队列中对象的 自然顺序(natural order),但是可以通过提供自己的 Comparator 来修改这个顺序。
PriorityQueue 确保在调用 peek() , poll() 或 remove() 方法时,获得的元素将是队列中优先级最高的元素。
public static void printQ(Queue queue) {
while (queue.peek() != null) {
System.out.print(queue.remove() + " ");
}
System.out.println();
}
public static void main(String[] args) {
// 默认自然排序
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++) {
priorityQueue.offer(rand.nextInt(i + 10));
}
DotThis.printQ(priorityQueue);
List<Integer> ints = Arrays.asList(25, 22, 20,
18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25);
priorityQueue = new PriorityQueue<>(ints);
DotThis.printQ(priorityQueue);
// reverseOrder
priorityQueue = new PriorityQueue<>(
ints.size(), Collections.reverseOrder());
priorityQueue.addAll(ints);
DotThis.printQ(priorityQueue);
// 自然排序
String fact = "EDUCATION SHOULD ESCHEW OBFUSCATION";
List<String> strings =
Arrays.asList(fact.split(""));
PriorityQueue<String> stringPQ =
new PriorityQueue<>(strings);
DotThis.printQ(stringPQ);
// reverseOrder
stringPQ = new PriorityQueue<>(
strings.size(), Collections.reverseOrder());
stringPQ.addAll(strings);
DotThis.printQ(stringPQ);
// 放到set里
Set<Character> charSet = new HashSet<>();
for (char c : fact.toCharArray()) {
charSet.add(c);
}
PriorityQueue<Character> characterPQ =
new PriorityQueue<>(charSet);
DotThis.printQ(characterPQ);
}public static void printQ(Queue queue) {
while (queue.peek() != null) {
System.out.print(queue.remove() + " ");
}
System.out.println();
}
public static void main(String[] args) {
// 默认自然排序
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++) {
priorityQueue.offer(rand.nextInt(i + 10));
}
DotThis.printQ(priorityQueue);
List<Integer> ints = Arrays.asList(25, 22, 20,
18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25);
priorityQueue = new PriorityQueue<>(ints);
DotThis.printQ(priorityQueue);
// reverseOrder
priorityQueue = new PriorityQueue<>(
ints.size(), Collections.reverseOrder());
priorityQueue.addAll(ints);
DotThis.printQ(priorityQueue);
// 自然排序
String fact = "EDUCATION SHOULD ESCHEW OBFUSCATION";
List<String> strings =
Arrays.asList(fact.split(""));
PriorityQueue<String> stringPQ =
new PriorityQueue<>(strings);
DotThis.printQ(stringPQ);
// reverseOrder
stringPQ = new PriorityQueue<>(
strings.size(), Collections.reverseOrder());
stringPQ.addAll(strings);
DotThis.printQ(stringPQ);
// 放到set里
Set<Character> charSet = new HashSet<>();
for (char c : fact.toCharArray()) {
charSet.add(c);
}
PriorityQueue<Character> characterPQ =
new PriorityQueue<>(charSet);
DotThis.printQ(characterPQ);
}